Introduction to Hadoop Distributed File System (HDFS)
In this blog, you will learn about Hadoop Distributed File System, features of HDFS and Architecture.
The Hadoop Distributed File System (HDFS) is designed to store huge data sets reliably and to flow those data sets at high bandwidth to user applications. It is run on commodity hardware.
In a large cluster, thousands of servers both host directly attached storage and execute user application tasks. By sharing the storage and computation across multiple servers, the resource can grow with demand it will remain cost-effective at every size.
HDFS is based on the Google File System (GFS) and written completely in Java programming language.
What are main Features of HDFS?
The most important features are:
- Fault Tolerance:
It controls faults by the process of copy making. The replica of users data is produced on different machines in the HDFS cluster. It is highly fault-tolerant.
Hadoop framework divides data into blocks. After that produces multiple copies of blocks on different machines in the cluster.
So, if any machine in the cluster goes down, then a client can simply access their data from another machine which contains the same copy of data blocks.
- High Availability:
It is an extremely available file system and data gets replicated with the nodes in the Hadoop cluster by generating a replica of the blocks on the different slaves present in HDFS cluster. So, whenever a user needs to access this data, they can obtain their data from the slaves which contain its blocks.
At the moment of critical positions like the crash of a node, a user can quickly access their data from the different nodes. Because duplicate copies of blocks are already on the other nodes in the HDFS cluster.
- High Reliability:
HDFS provides reliable stores data in the range of 100s of petabytes. HDFS stores data reliably on a cluster. HDFS stores data reliably by creating a replica of each and every block present in the cluster. If the node in the cluster containing data goes down, then a user can easily access that data from the other nodes.
HDFS by default creates 3 replicas of each block containing data present in the nodes. So, data is quickly available to the users. Hence user does not face the problem of data loss. Thus, HDFS is highly reliable.
- Replication:
Data Replication is one of the most important and unique features of Hadoop HDFS.The data is replicated across a number of machines in the cluster by creating blocks. The process of replication is maintained at regular intervals of time by HDFS and HDFS keeps creating replicas of user data on different machines present in the cluster. The user can access the data easily. Hence there is no possibility of loss of user data.
- Scalability:
Hadoop HDFS stores data on multiple nodes in the cluster. So, whenever requirements increase you can scale the cluster. Two scalability mechanisms are available in HDFS: Vertical resources are (CPU, Memory & Disk) and Horizontal Scalability (more machines in the cluster).
- Distributed Storage:
In HDFS all the features are achieved via distributed storage and replication. HDFS data is stored in a distributed manner across the nodes in HDFS cluster. In HDFS data is divided into blocks and is stored on the nodes present in HDFS cluster.
And then replicas of each and every block are created and stored on other nodes present in the cluster. So, if a single machine in the cluster gets crashed we can easily access our data from the other nodes which contain its replica.
HDFS Architecture:
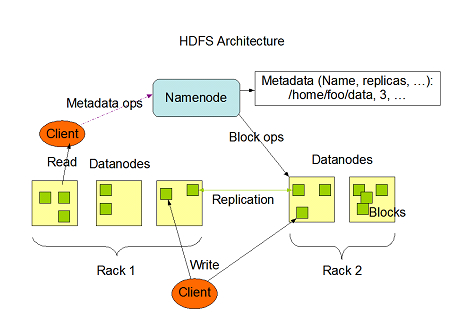
HDFS follows the master-slave architecture and it has the following elements.
- Namenode.
- Datanode.
- Block.
- Namenode:
The Namenode is the commodity hardware that includes the GNU/Linux operating system and the Namenode software. It is a software that can be worked on commodity hardware. The system must have the Namenode acts as the master server and it does the following tasks:
- Manages the file system namespace.
- Regulates client’s access to files.
- It means executes file system operations such as renaming, closing, and opening files and directories.
- Datanode:
The Datanode remains as commodity hardware and having GNU/Linux operating system and Datanode software. As every node (commodity hardware/System) into the cluster, it will be present in Datanode. These certain nodes control the data storage of their system.
- These Datanodes performs on read-write operations on the file systems, as per client request.
- It also performs in operation such as block creation, deletion, and replication into instructions of the Namenode.
- Block:
Usually, the user data is stored in the files of HDFS. The data in a file system will be classified into one or more segments and/or stored in single data nodes. Certain file segments are called as blocks.
In other words, the least amount of data that in HDFS can read or write is called a Block. The default block size is 64MB, although it can be developed as per the requirement configuration in HDFS will change.
HDFS Assumption and Goals:
- Hardware failure:
Hardware failure is basically the norm instead of the exception. An HDFS instance consists of hundreds or thousands of server machines, each consuming the storing part of the file system’s data.
The real fact is that there are a large number of components and that each component consists of the non-trivial probability of failure which explains that some of the components of HDFS are always non-functional.
- Large datasets:
HDFS always needs to work with large datasets. Standard practice is to have a file in HDFS of size ranging from gigabytes to terabytes. The design of HDFS architecture is such a way that it is best to store and retrieve a huge amount of data.
HDFS should provide high aggregate data bandwidth. It should also be able to scale up to hundreds of nodes on a single cluster. It should be good enough to deal with tens of millions of files on a single instance.
- Streaming data access:
HDFS applications require streaming access to their datasets. Hadoop HDFS is essentially designed for group processing rather than interactive use by users. The force is on the large throughput of data access rather than low latency of data access. It concentrates on how to retrieve data at the quickest possible speed while analyzing logs.
- Portability across heterogeneous hardware and software platforms:
HDFS is created with portable quality to be portable from one platform to other. This allows widespread adoption of HDFS. It is the great platform while dealing with a large set of data.
- Simple coherency model:
It serves on theory write-once-read-many access model for files. Once the file is designed, written and closed should not be changed. This fixes the data coherency issues and allows high throughput data access. A MapReduce-based application or web crawler application perfectly fits in this model. As per apache notes, there is a plan to support appending writes to files in the future.

Chandanakatta
Author
Hey there! I shoot some hoops when I’m not drowned in the books, sitting by the side of brooks.