MultiNode Cluster Installation Guide
Multinode cluster in Big data:
A Hadoop cluster is a special type of computational cluster designed specifically for storing and analyzing huge amounts of unstructured data in a distributed computing environment.
Machines in the clusters work as Master and Job Tracker, while the remaining clusters act as slave clusters for both data node and task tracker.
Hadoop clusters are referred as sharing systems because the only thing that is shared between nodes is the network that connects them.
They are well recognized for boosting the speed of data applications. They are highly scalable as a cluster’s processing power is affected by growing volumes of data, additional cluster nodes can be added to increase throughput.
These clusters are highly resistant to failure because each piece of data is copied onto other cluster nodes, which ensures that the data is not lost if one node fails.
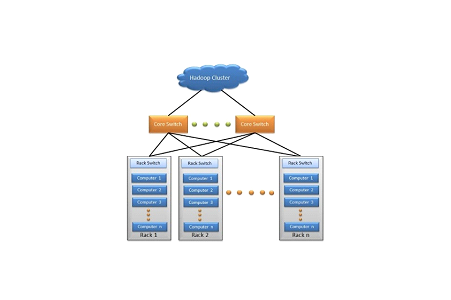
What is a multinode cluster?
In a multi-node Hadoop cluster, all the required essentials run on different machines.
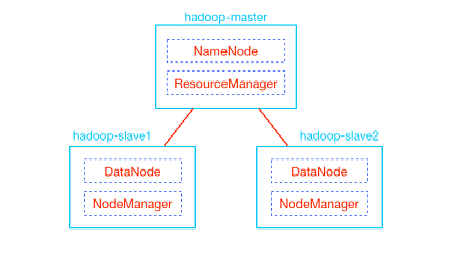
A multi-node Hadoop cluster setup has master-slave architecture wherever in one machine acts as a master that runs the Name Node daemon while the other machines act as a slave or worker nodes to run other Hadoop processes.
The main reason why Hadoop is well suited to this type of data is that Hadoop works by breaking the data into pieces and assigning each “piece” to a specific cluster node for analysis.
Java is the main requirement for Hadoop. To set-up a Multinode cluster, these are the commands which we have to follow:-
- First, we should verify the existence of java in our system using “java -version”. The syntax of java version command is given below.
| $ java -version |
- If the given command works fine, then it will give output as below.
java version “1.7.0_71” Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot (TM) Client VM (build 25.0-b02, mixed mode) |
- Another way to install the java by visiting the following link here.
We will find java downloaded to our system.
$ cd Downloads/ $ ls jdk-7u71-Linux-x64.gz $ tar zxf jdk-7u71-Linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-Linux-x64.gz |
- To make the availability of java to all the users, we have to move it to the location “/usr/local/” where we can find easily. Open the root, and type the following commands.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit |
- For setting up PATH and JAVA_HOME variables, use the following commands to a~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin |
Here we have to verify java version command from the above process and we have to install java on all our cluster nodes.
- Now, create a system user account on both master and slave systems for the Hadoop installation.
# useradd hadoop # passwd hadoop |
- Here we have to edit hosts file in /etc/ folder on all nodes and specify the IP address of each system followed by their hostnames for mapping the nodes.
# vi /etc/hosts enter the following lines in the /etc/hosts file. 192.168.1.109 hadoop-master 192.168.1.145 hadoop-slave-1 192.168.56.1 hadoop-slave-2 |
- Setup ssh in every node such that they can communicate with one another without any prompt for a password for key based login.
# su hadoop $ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2 $ chmod 0600~/.ssh/authorized_keys $ exit |
- In the Master server, download and install Hadoop using the following commands.
# mkdir /opt/hadoop # cd /opt/hadoop/ # wget: http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz # tar -xzf hadoop-1.2.0.tar.gz # mv hadoop-1.2.0 hadoop # chown -R hadoop /opt/hadoop # cd /opt/hadoop/hadoop/ |
Configuration of Hadoop:
You can configure Hadoop server by making the changes:-
Core-site.xml
Open the core-site.xml file and edit it as shown below.
fs.default.name hdfs://hadoop-master:9000/ dfs.permissions false |
hdfs-site.xml
Open the hdfs-site.xml file and edit it as shown below.
dfs.data.dir /opt/hadoop/hadoop/dfs/name/data true dfs.name.dir /opt/hadoop/hadoop/dfs/name true dfs.replication 1 |
mapred-site.xml
Open the mapred-site.xml file and edit it as given below.
mapred.job.tracker hadoop-master:9001 |
hadoop-env.sh
Open the hadoop-env.sh file and edit JAVA_HOME, HADOOP_CONF_DIR, and HADOOP_OPTS as below.
| export JAVA_HOME=/opt/jdk1.7.0_17 export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true exportHADOOP_CONF_DIR=/opt/hadoop/hadoop/conf |
Installing Hadoop:
Install Hadoop on all the slave servers by following the given commands.
# su hadoop $ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop $ scp -r hadoop hadoop-slave-2:/opt/hadoop |
Configuring Hadoop on Master Server:
Open the master server and configure it by following the given commands.
# su hadoop $ cd /opt/hadoop/hadoop |
The commands shown below is used for Configuring Master Node.
$ vi etc/hadoop/masters hadoop-master |
For Configuring Slave Node have to follow the below command.
$ vi etc/hadoop/slaves hadoop-slave-1 hadoop-slave-2 |
The following is used to Format Name Node on Hadoop Master.
# su hadoop $ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format |
11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop-master/192.168.1.109 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.0 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473; compiled by ‘hortonfo’ on Mon May 6 06:59:37 UTC 2013 STARTUP_MSG: java = 1.7.0_71 ************************************************************/ 11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap editlog=/opt/hadoop/hadoop/dfs/name/current/edits …………………………………………………. …………………………………………………. …………………………………………………. 11/10/14 10:58:08 INFO common.Storage: Storage directory /opt/hadoop/hadoop/dfs/name has been successfully formatted. 11/10/14 10:58:08 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15 ************************************************************/ |
Benefits of Multinode cluster:
- i) The benefit of using Hadoop clusters is that they are ideally suited to analyzing big data. Big data tends to be widely distributed and largely unstructured.
- ii)It is cost effective as the required software for Hadoop is open source.
iii) Another benefit is scalability as big data is always growing.
- iv) Big data is most useful when it is analyzed in real time or proximity to real time.
- v)Hadoop clusters are flexible to crash. So, when a piece of data is sent to a node, it is also replicated to other cluster nodes.
Drawbacks of Hadoop clusters:
- i) The clustering resolution is based on the opinion that data can be “taken apart” and explained by parallel processes operating on separate cluster nodes.
- ii)There is an important learning curve associated with building, operating and supporting the cluster which is missing.
If you wish to dive deeper, know more and establish yourself in to Big Data, click here and read up.

Chandanakatta
Author
Hey there! I shoot some hoops when I’m not drowned in the books, sitting by the side of brooks.