Informatica MDM Load and Match Process – Tutorial
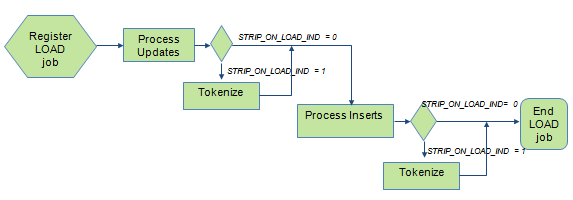
Load Process:
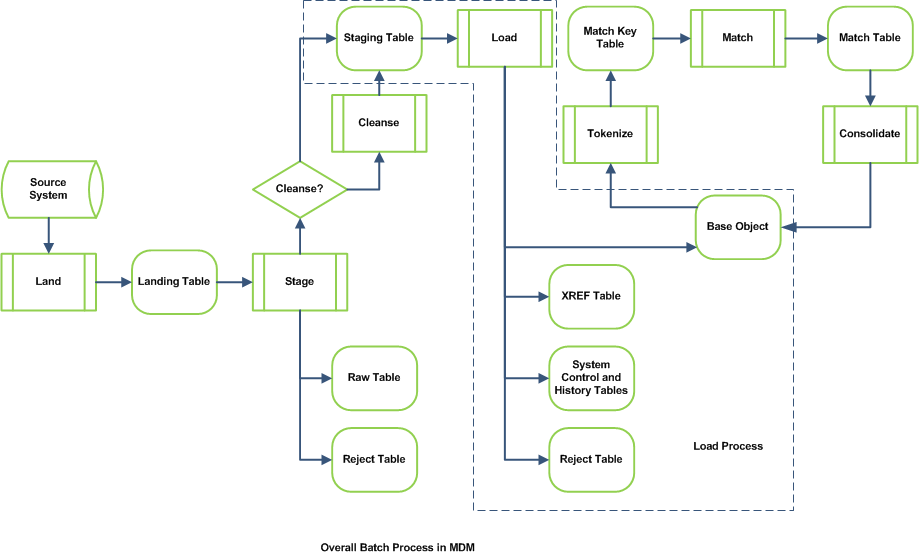
Load process is a two-step process:
- Apply Updates.
- Apply Inserts.
Updates
- Load job applies updates for existing records whose.
LAST_UPDATE_DATE (Staging table) > SRC_LUD (XREF table).
- The update process always updates the XREF table record.
- The update process may update the Base Object depending on trust:
- For columns not flagged for trust, update happens if incoming data has new LUD.
- For columns flagged for trust, load job compares trust weightings of staging table data to trust weightings of existing data in base object to determine what can be updated.
- If history flag is switched on for the Base Object, then the update process writes to the history tables of Base Object and XREF.
Inserts
- Load job applies inserts for records that do not exist in the XREF table.
- ROWID_OBJECT values are generated for the new records.
- New records are inserted into a base object and XREF with CONSOLIDATION_IND = 4.
- If history flag is switched on for the Base Object, then the insert process writes to the history tables of Base Object and XREF.
Rejects
- Referential Integrity is maintained among base objects in the consolidated data model.
- Rejects will occur in the load process if any records violate the RI constraint.
- Parent records do not exist.
- Child records are loaded before the parent records.
- Lookup has been defined incorrectly.
- Rejected records are inserted in the reject table of the Staging table.
staging_table_name_REJ
Match Process:
Objectives:
Following are the objectives of this topic:
- Match & Merge Overview.
- Match Rules Configuration.
- Exact Match/Search Strategy.
- Fuzzy Match/Search Strategy.
- Match Server Architecture.
Match & Search Strategy:
Match Process:
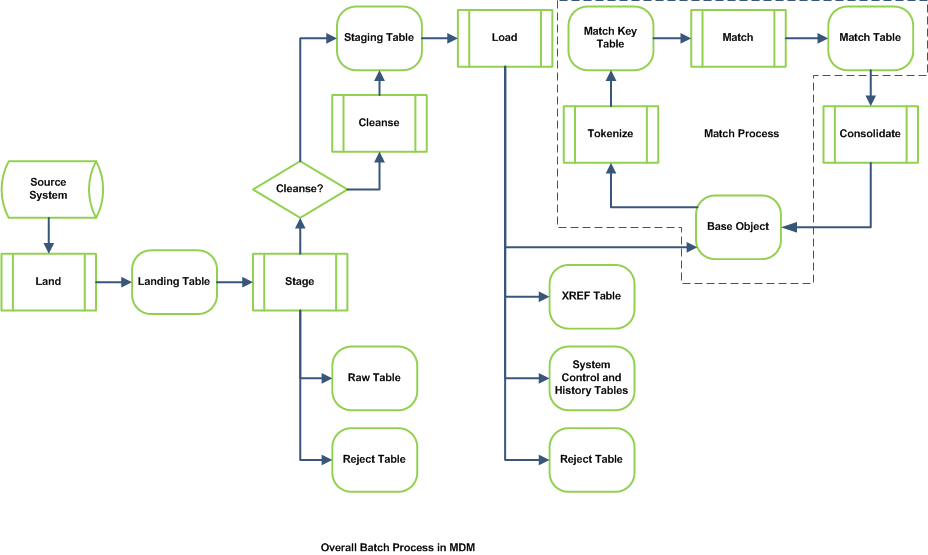
Match & Merge Overview:
Challenges with identifying duplicate records.
- Misspellings, typing, and transcription errors.
- Nicknames.
- Synonyms.
- Abbreviations.
- Foreign and Anglicized words.
- Prefix and suffix abbreviations.
- Concatenation or splitting of words.
- Noise words and punctuation.
- Casing and character set variations.
- To merge or link records, MRM needs to know which records are likely duplicates of each other.
- Match rules tell MRM how to identify likely duplicates.
- Match rules also tell MRM if two matching records are similar enough to automatically merge/link, or if they should be reviewed by a data steward.
Data Consolidation Options.
- Merging (merge-style base objects) physically combines the matched records in the base object. Makes the most-current best version of the truth (BVT) available.
- Linking (link-style base objects) quickly determines the BVT without physically combining the records. Provides much faster overall throughput.
Match/Search Strategy:
Exact
- Does not allow for any variations in the data in the match columns.
- Very simple match process, therefore fast.
Fuzzy
- Allows for variations in spelling, formats, word order, nicknames, synonyms, etc.
- More complex match process, therefore slower.
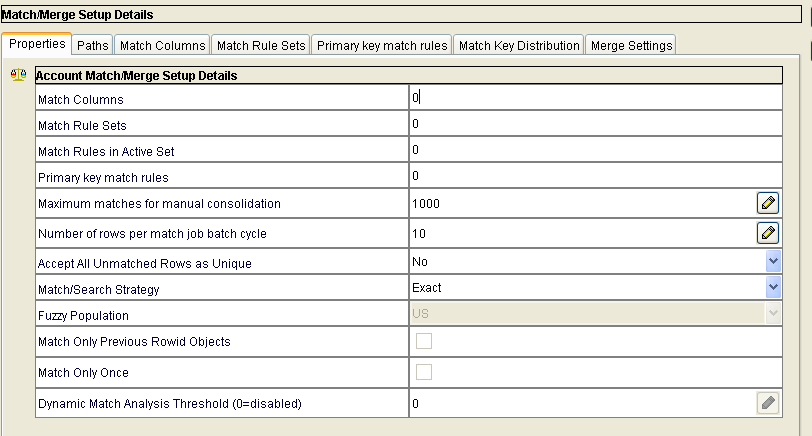
High-level process flow for the match process:
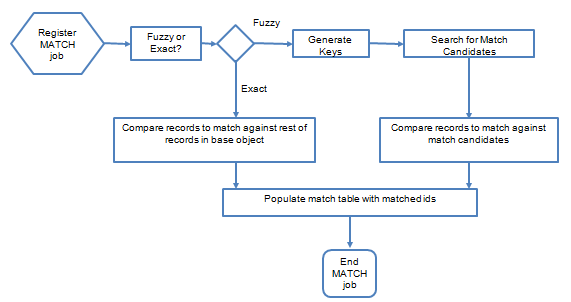
Match Path
- A Match Path represents the base object which will provide data for matching purpose.
- Traverse the hierarchy between records across multiple base objects or within a single base object.
- Foreign Key Relationships between tables are used to traverse the relationships.
- Parent-to-child or child-to-parent relationships can be specified.
Match Path – Check for Missing Children
- By default, MDM does an inner join between the base objects defined in the Match Path.
- The join, therefore, excludes rows that don’t have corresponding rows in the joined tables.
- To include those records, switch on “Check for Missing Children” – MDM will then do an outer join instead of an inner join.
Get Free Informatica MDM Materials
Match Path – Inter Table
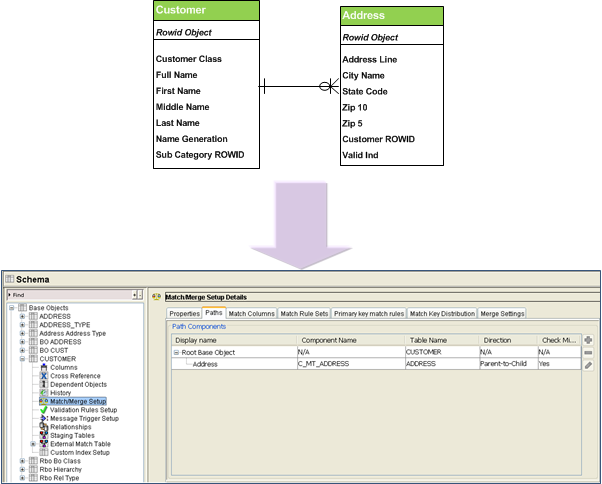
Match Path – Intra Table
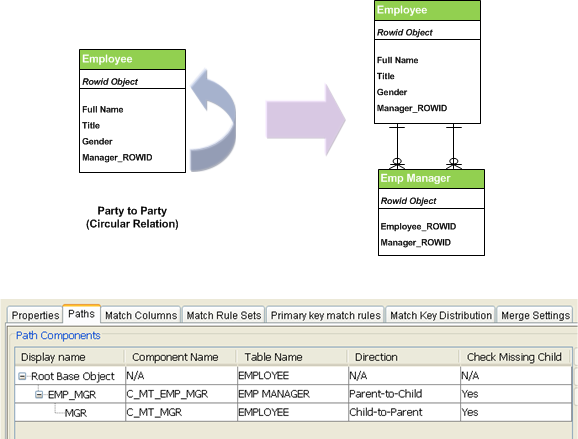
Match Column:
- A match column contains an identifying characteristic of the base object to be consolidated
- Each base object can have multiple match columns
- Examples:
1. Full Name.
2. Generation
3. Address
4. Phone
5. Email
- Provider column(s) is the base object columns that provide the data for the match column:
- Can be a single column or a concatenation of columns
- Must be a VARCHAR / CHAR column to concatenate
- Date column is also supported for matching
Each match column is based on one or more columns
- From base object.
- Or from X-ref (in some cases).
- Or from child base object (in some cases).
Exact Match/Search Strategy
Steps for defining Exact Match Rules
- Select Match/Search Strategy = Exact
- Define Match Path
- Define Match Columns
- Create at least one Match Rule Set
- Create Match Rules for Match Rule Set(s)
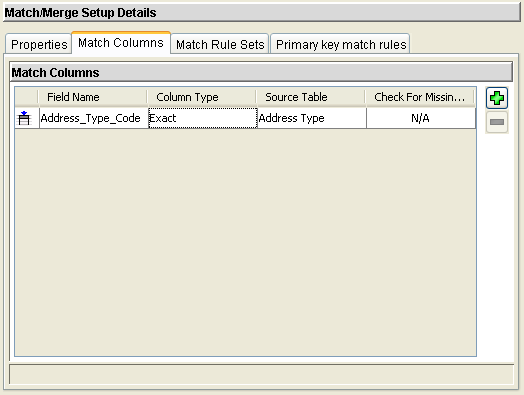
Match Columns
- A match column contains an identifying characteristic of the base object record to be consolidated
- Exact Match Columns:
- Does not make allowance for any variations in data content
- Records will match if they have identical values in the match columns used in match rules
Match Rule & Match Rule Set
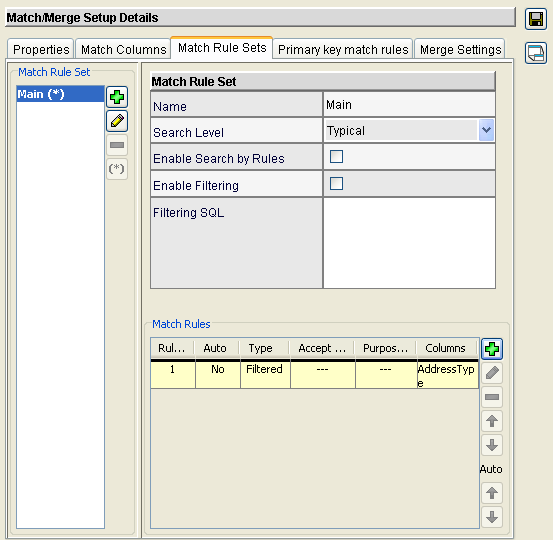
Match Rules are grouped into Match Rule Sets.
- Can define multiple rule sets.
- Only one match rule set can be active at any point in time.
Match rule defines the combination of columns that constitute a match.
Match Rule – Auto property
- Match rules are flagged either for auto merge/auto link or for manual merge/link.
- Matches resulting from auto merge/auto link rules will result in the records being automatically merged/linked to the system when the auto merge/auto link batch job runs.
- Matches resulting from manual merge/link rules will be queued for review by a data steward.
Match Rule & Match Rule Set
- Every checked Match Column adds an “And” condition.
- Every new Rule is an “Or” condition.
- Net result of match is that the same 2 records will only match once, on the first match rule that they match on.
Match Rule – Null Matching
- By default, NULL is not regarded as being the same as NULL.
- NULL Matches NULL: Use this flag to specify the match columns in a match rule that should be regarded as matches even if the 2 values being compared are both NULL.
- NULL Matches non-NULL: Use this flag to specify the match columns in a match rule that should be regarded as matches when one of the values being compared is NULL and the other is not.
Match Rule – Non-Equal Matching
- Specifies that 2 records are a match if they do not have the same values in the non-equal match column.
- Reverses whatever would/would NOT have matched without Non-equal match.
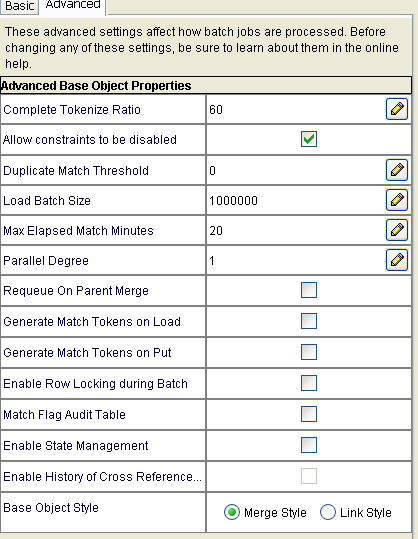
- If using non-equal match, then MUST switch on Validate Matches property in Base Object Advanced Properties.
Match Rule – Segment Matching
- Allows a match rule to be limited to a specific subset of data.
- Different match rules can use different segment values.
Match Rule
Fuzzy Match/Search Strategy:
Steps for defining Fuzzy Match Rules
- Select Match/Search Strategy = Fuzzy
- Choose a Population
- Define Match Path
- Define Match Key
- Define Match Columns
- Create at least one Match Rule Set & choose Search Level
- Create Match Rules for Match Rule Set(s)
Population
- Population is intended to addresses the name distribution problem.
- Common family names in each population skew the data and query performance.
E.g. Smith, Williams in English-speaking populations.
- Each population also has a large number of uncommon names that tend to have the most error and variability.
- Match needs to account for both of these situations in the way that the keys are built, to give optimal search performance for both.
- Defines how to identify matches within a particular population and language.
- Defines how to build keys and perform searches on name and address.
- Supports a specific set of match purposes.
Match Key
- Match key is used to search for match candidates.
- It is a fixed-length, compressed, and encoded value.
- Built from a combination of the words and numbers in a name or address.
- For one name or address, multiple SSA match keys are generated.
- Match Key Properties:
- Key Type.
- Key Width.
- Path Component.
- Match Column Contents.
Match Key – Key Type
- The match key type describes important characteristics about a column to MDM Hub.
- Should be based on the main identifying data in your base object.
- For standard population, the options are:
Match Key – Key Width
- Determines the degree of variance that will be supported in the key values.
- Represents tradeoff between match precision and the space used by match key records.
Match Key – Path Component
- Contains the column that forms the basis for defining the Match Key.
- Can be any table defined in the Match Path.
Match Key – Match Column Contents
- The column(s) from Path Component that provides data to the Match Key.
Match Key – Example
- Key Type = Organization_Name;
- Key Width = Standard;
- Path Component = Customer
- Match Column Contents = Full_Name
Match Key:
Match Column
- A match column contains an identifying characteristic of the base object record to be consolidated.
- Can be a fuzzy column or an exact column.
- Fuzzy Match Column.
- The column name you choose defines the type of data that the match expects that column to contain.
- Examples: Person Name, Address Part 1, Address Part 2, etc.
- Exact Match Column.
- Acts as a filter in the match.
- Can have additional properties when used in match rules like Null match, Non-equal match, and segment match.
Match Column:
Match Rule Set
- They are logical grouping of Match Rules that collectively act on a base object for identifying duplicates.
- Multiple rule sets can be defined for a base object.
- Only one rule set can be active at any point in time.
- Each rule set has a Search Level and can comprise of one or more Match Rules.
Match Rule Set – Search Level
Determines how many match candidates are returned in the search phase of match process.
Match Rule Set – Search Level Examples
Key Type = Organization_Name; Key Width = Standard;
Record to be Matched = “ELIZABETH S O’BRIAN”
Match Rule Set:
Match Rule
- Determines what constitutes a match during match process
- Fuzzy Match Rule Properties:
- Match Purpose
- Match Level
- Accept Limit Adjustment
Match Rule – Match Purpose
- Determines the fields that will be used in the match
- Different fields are required fields for different purposes
- There are also optional fields for each purpose that can help improve the match
- Determines the importance accorded to each field
Match Rule – Match Level
- Determines how precise the match is i.e. how similar a candidate record is to the queued record to be considered a match
- Supported match levels are:
- Conservative: Tight Matching
- Typical: Appropriate for most matches
- Loose: Allows more variance in the values being matched
Match Rule – Accept Limit Adjustment
- Determines the acceptability of a match for the specified match level.
- The Accept Limit Adjustment allows a coarse adjustment to what is considered to be a match for this match rule:
- A positive adjustment results in tighter matching.
- A negative adjustment results in looser matching.
Match Rule:
Match Rule – Syntax Used in Rule Description
Match Server Architecture
Match server is multi-threaded
- Can configure how many threads MDM Hub will create for matching.
- If not configured, 4 threads will be created regardless of the number of CPUs on the machine.
Multiple match servers can be configured
- Allows match jobs to be run in parallel. A single match job is not load balanced across multiple match servers.
- MDM Hub will assign match jobs to available match servers on a round robin basis
Merge Process:
Objectives
Following are the objectives of this topic:
- Configure Merge Settings
- Describe Immutable Source Systems
- Describe Distinct Systems
- Describe the Un-Merge Process
Merge Process
Merge
- Consolidation process of two matched records in the Base Object
- Merge can be Auto-Merge or Manual-Merge depending on the degree of matching.
Immutable Source Systems
- An immutable source means that the source system is seen as a distinct source
- All records coming from this source always have a consolidation indicator of 1
- If two immutable records must be merged, then a data steward needs to perform a manual verification in order to allow that change. The data steward will have to choose the key that remains
Distinct Systems
- Records from source marked as Distinct will not merge amongst themselves
Un-Merge Process
- By default, unmerging parent records does not unmerge associated child records
- Unmerge Child When Parent Unmerges option allows you to specify what happens if records in the parent base object are unmerged
- Pre-Requisites for enabling this option are:
- The parent-child relationship must already be configured in the child base object.
- The foreign key column in the child base object must be a match-enabled column.
From this blog you have gone through Match process and to have knowledge in Informatica MDM Batch Viewer.

Nitesh
Author
Bonjour. A curious dreamer enchanted by various languages, I write towards making technology seem fun here at Asha24.