Guide on Informatica MDM Staging – 2018
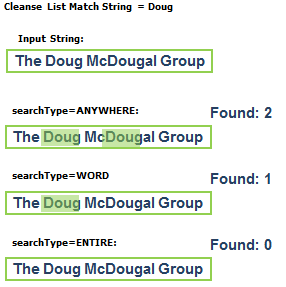
Staging Table:
Intermediate table between landing table and target table.
Belongs to one specific source system.
Staging table columns are selected sub-set of user-defined columns in target table.
Important/mandatory columns in a stage table:
LAST_UPDATE_DATE – Date on which record was last updated in the source system
PKEY_SRC_OBJECT – Primary key from the source system
SRC_ROWID – Database internal Rowid column
Stage Process:
Objectives:
Following are the objectives of this topic:
Configure Basic Mappings
Configure Cleanse Functions and Cleanse Lists
Configure Advanced Mappings
Configure Delta Detection and Audit Trail
Describe the Stage Process
Basic Mappings:
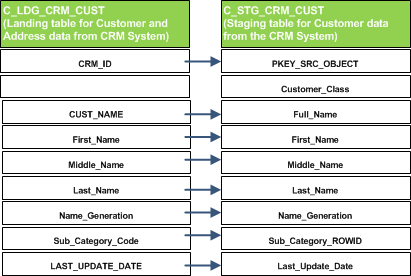
Mapping defines the movement of data from a landing table to a staging table.
Basic mappings are simple copy-column mappings without any data standardization or change in the column values.
A faster way to create a basic mapping in MDM is by using the “Auto Mapping” button that automatically maps landing and staging columns with the same name.
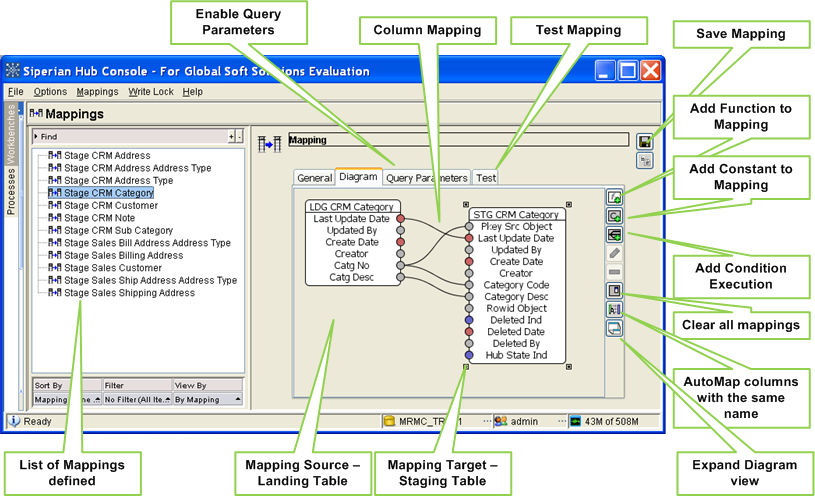
Demo – Mappings Tool:
Get Free Informatica MDM Materials
Mappings – Query Parameters:
Query Parameters are optional parameters that allow users to influence how data is selected from landing tables for processing.
Two types of query parameters are available
Enable Condition:
Stage process will select all the records in the landing table that meet the specified filter criteria.
Requires a SQL WHERE clause fragment to be specified as a filter.
Enable Distinct:
Stage process will select only the distinct set of values of the mapped columns from the landing table.
Mappings – Test Mappings:
The Test tab in the mapping tool allows users to enter input values in the format of landing table and shows the resultant values that would be placed in staging table
Input Area represents landing table columns.
Output Area represents staging table columns.
Advanced Mappings:
Advanced mappings support the various data cleansing and/or transformation logic required for cleaning the input source data
Functionality to add external data cleansing and address verification tools also like Trillium, Address Doctor, IDQ, etc.
A column map can include the following transformation options:
a) Function.
b) Constant.
c) Conditional Execution Statements.
d) Combination of all the above.
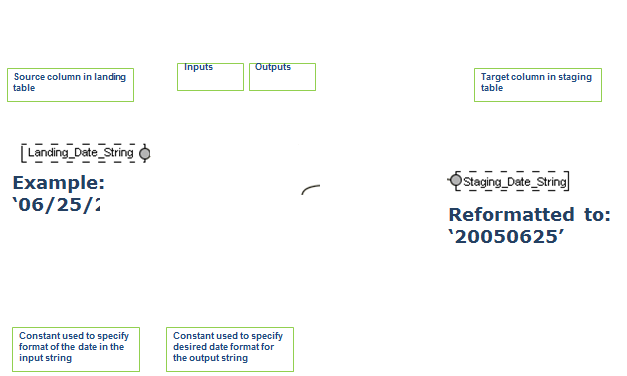
Advanced Mappings – Example:
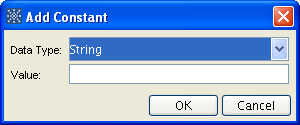
Constants:
Can be Boolean, Date, Float, Integer, or String.
Useful for providing default values to staging table columns.
Useful for providing input values for different functions.
Conditional Execution Component:
Equivalent to a case statement
Allows different cleansing depending on an input value
Consists of a set of case values and a case graph for each case value
Each case graph contains the steps to perform when the input to the condition equals the case value
Functions:
Functions are used for cleansing and transforming data in MDM
Each function has a set of Inputs and Outputs
An Input can be mapped from
A landing table column
A constant
An output from another function
An Output can be mapped to
A staging table column
An input from another function
Types of Functions:
i. Predefined Functions
ii. Cleanse Lists
iii. Cleanse Functions/Graph Functions
Pre-Defined Functions:
Informatica MDM comes with a list of pre-defined function that could be used to perform various data transformation activities.
Types of pre-defined functions:
Data Conversion Functions: Coverts one data type to another. Examples – Format function converts Boolean, date, or integer to string.
Logic Functions: Performs logical comparisons and checks on different data types. Examples – Boolean AND, OR, and NOT functions, is…Null functions.
Math Functions: Performs math operations on integer and decimal data types. Examples – Add, Subtract, Multiply, Divide, Ceiling, Floor function.
String Functions: Performs various transformation operations on string data types. Examples – Space, Whitespace, Case, Concatenate function.
Miscellaneous Functions: Other pre-defined functions. Examples – Now function, Read database function, Reject function.
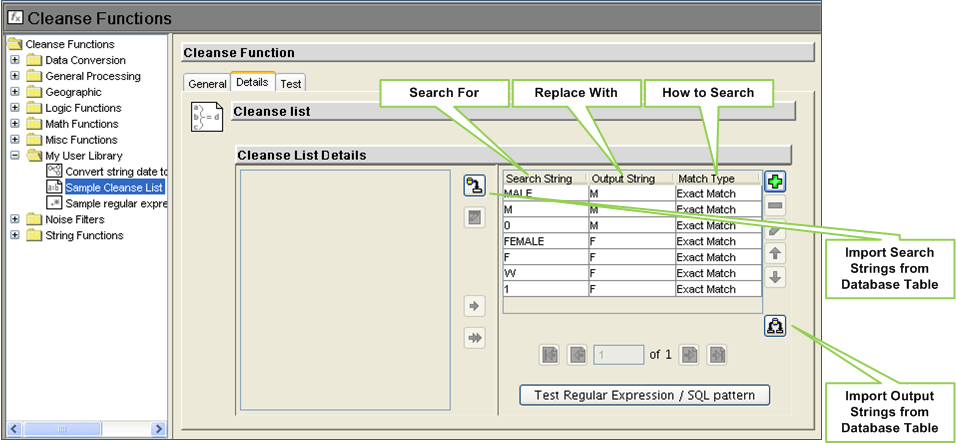
Cleanse List:
A cleanse list is a user-defined list of search and replace values.
Used for standardizing known string values, standardizing code values, and removing “noise” or punctuation from input strings.
Cleanse List Output:
Output String: Output value of the cleanse list function.
Matched: Last matched value of the cleanse list.
Match Flag: Indicates whether a match was found in the cleanse list of not.
Cleanse List: Flag.
Cleanse List Input – searchType
i) ANYWHERE to find the items anywhere in the input.
ii) WORD to compare cleanse list items with words in the input.
iii) ENTIRE to compare cleanse list items with the entire input string.
iv) The default value is ENTIRE.
Stage Process:
Data load from the landing tables into the source-specific staging tables.
Stage jobs execution is independent with respect to other stage jobs.
Delta Detection:
Property of the Staging Table
Only available if the “Contains Full Data Set” landing table property is switched on
Process of identifying new and changed records from the source system by comparing the source system’s current data set with the previous dataset
Deltas are determined by comparing landing table data with previous landing table data
Two options for determining deltas:
On a change in date column (LAST_UPDATE_DATE) in the landing table
On a change in any column other than the LAST_UPDATE_DATE
Previous Landing Table:
Property of the Staging Table
A snapshot of the landing table columns and data from the end of the previous stage job
Used for Delta Detection
Can be used for Hard Delete Detection
Table name format: staging_table_name_PRL
Audit Trail / RAW Table:
Property of the Staging table
This table stores a history of the raw data, as stored in the landing table at the start of the stage process
Audit trail retention period can be specified
Table name format: staging_table_name_RAW
Rejects:
Rejects can occur in the Stage Process if:
Data Conversion Error occurs
Target Column size is small
Duplicate primary keys in the data
Reject function called from the mapping
Table name format: staging_table_name_REJ
The load process also uses the same reject table as the stage process
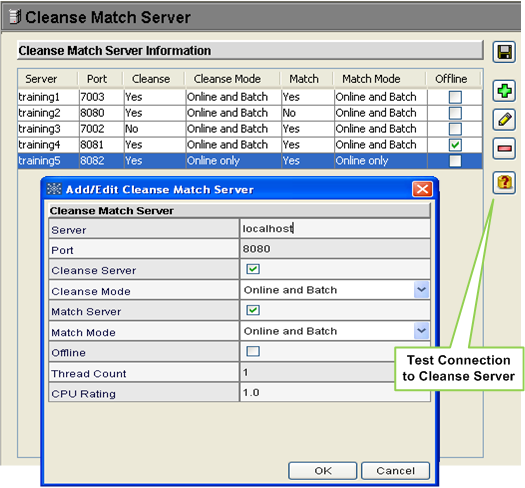
Process Server:
Server for handling cleansing or matching requests from MRM.
Informatic MDM provides functionality for registering multiple cleanse match servers.
Servers can be cleansed only, match only, or both.
Load Process:
Objectives:
Following are the objectives of this topic:
Configure Trust.
Configure Validation Rules.
Configure Relationships.
Configure Lookups.
Describe the Load Process.
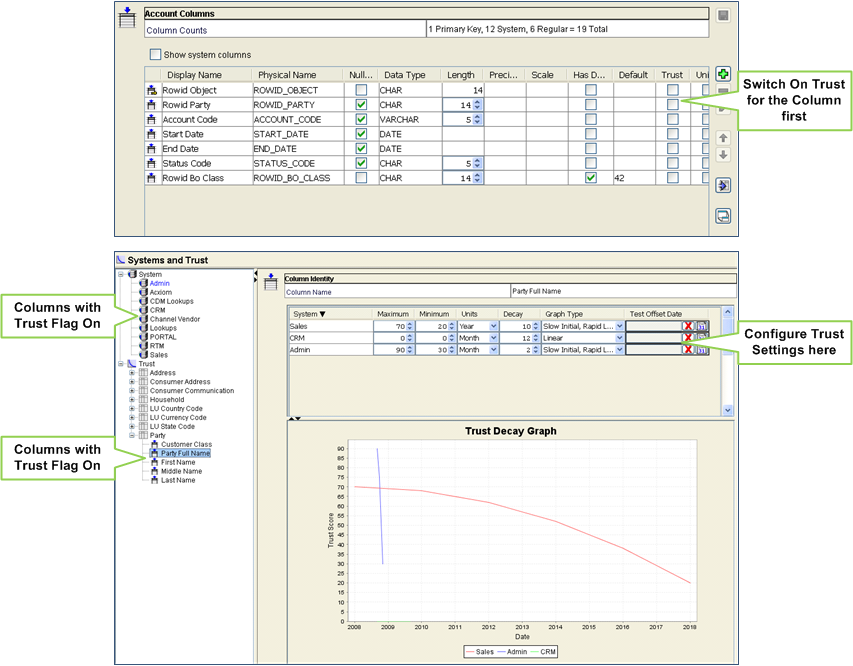
Trust:
Dynamic Cell-level Survivorship.
Base Object property.
A mechanism for measuring the confidence factor associated with each cell based on its source system, change history, and other business rules.
Defined at a column level for each contributing source system.
Ensures that the most reliable data at the cell level is consolidated based on data characteristics.
When two base object records merge:
MRM calculates the trust for each trusted column in the two base object records being merged.
The cell with the highest value survives in the final merged record.
When an update comes in from a source:
MRM calculates the trust on the incoming data and compares it to the trust of the data in the base object.
Updates are only applied to the base object for cells that have higher trust on the incoming data.
Trust is an options property for a base object column.
If trust is switched off for a column, then the most recently updated value from any source is the survived value in the base object.
Only switch on trust for a column if:
Two or more source systems contribute to the column.
The sources are not deemed to be equally reliable providers of values to the column.
Factors affecting trust score:
Source of the Data – Each trust enabled column must have a maximum and minimum trust weighting assigned for each source system.
Decay period for Data – Each trust enabled column must have a decay period assigned for each source system that tells how long the trust weighting takes to drop from maximum trust to minimum trust.
Decay Type – Each trust enabled column must have a decay type assigned for each source system that tells how the trust value decreases from maximum to minimum during the decay period.
Trust Demo:
Validation Rules:
Defines a condition under which a data value is not valid.
Base Object property.
If the validation condition is met, then trust weighting is downgraded.
Trust after validation downgrade is
TRUST – (TRUST * downgrade_pct/100)
Reserve Minimum Trust can be set to avoid having trust scores below the minimum trust value
x := TRUST – (TRUST * downgrade_pct/100)
if x < MINIMUM_TRUST then x := MINIMUM_TRUST
endif;
Validation check can be done on any column in a base object and Downgrade can be applied to any other columns in the base object.
Some examples of validation rules:
Downgrade trust on the Last Name if
length(last_name)<3 and last_name <> ‘NG’
Downgrade trust on Middle Name if
middle_name is null
Downgrade trust on Address Line 1, City, State, Zip, and Valid Address Ind if
valid_address_ind = ‘False’
Validation Rules Demo:
Relationships:
Relationships are the association between base objects via a matching column.
Property of the Base Object.
Types of relationships:
i) One to Many Relationship.
ii) Many to Many Relationship.
One-to-many Relationship:
One table (the child) contains a foreign key column, which matches a unique key column of another table (the parent).
One-to-many relationships are always defined from the child table in the relationship (i.e. the referencing table rather than the referenced table).
Many-to-many Relationship:
A base object acts as an intersection table between another two-base object.
The intersection table has a one-to-many relationship with the other two base objects.
Lookups:
Lookups are translation of source’s primary or foreign key value into corresponding base object key value
Configured on the Staging Tables.
Two types of lookups:
Automatic lookups for loading primary keys.
User-defined lookups for loading foreign keys.
Automatic Lookups:
MRM automatically handles lookups loading/updating the primary key of a Base Object.
Shadow Foreign Key:
The foreign key value stored on the cross-reference (X-ref) is the same as the value stored on the base object.
This facilitates certain MRM internal processes on parent merge.
However, it makes it difficult to tie child X-ref’s back to their original parent X-ref.
Shadow foreign key is an additional column added to the X-ref for every foreign key defined on the base object.
Contains the source system’s original foreign key value.
Name of shadow foreign key column is S_FKColumnName, for example
Foreign key column name = Customer_ROWID
Shadow foreign key column name = S_Customer_ROWID
Here, you can have a look about MDM materials. If you have any doubts also you will get clarification by these blog.

Chandanakatta
Author
Hey there! I shoot some hoops when I’m not drowned in the books, sitting by the side of brooks.