SAP HANA Architecture
What is SAP HANA Architecture?
Various aspects are relevant to the SAP HANA Architecture.
This platform comprises of several components.
The key distinctions between HANA and the previous generation of SAP systems, are that it is a column-oriented, in-memory database that combines OLAP and OLTP operations into a single system. Thus, in general, SAP HANA is an OLTAP system.
Storing data in main memory rather than on disk provides faster data accessing and by extension faster querying and processing.
While storing data in-memory confers performance advantages, it is a more costly form of data storage.
Observing data access patterns up to 85% of the data in an enterprise system may be infrequently accessed, therefore, it can be cost-effective to store frequently accessed, data in-memory while the less frequently accessed data is stored on disk, an approach SAP is termed “Dynamic tiering“.

Column-oriented systems store all the data for a single column in the same location, rather than storing all the data for a single row in the same location (row-oriented systems).
This enables performance improvements for OLAP queries on the large data sets and allows the greater vertical compression of similar types of data in a single column.
If the read time for column-store data is fast enough then consolidated viewing of the data can be done on the fly by removing the need for maintaining aggregate views, and it is associated with the data redundancy.
Although row-oriented systems have traditionally been favored for OLTP, in-memory storage opens techniques for the development of hybrid systems, suitable for both OLAP and OLTP capabilities, removing the need to maintain separate systems for OLTP and OLAP operations.
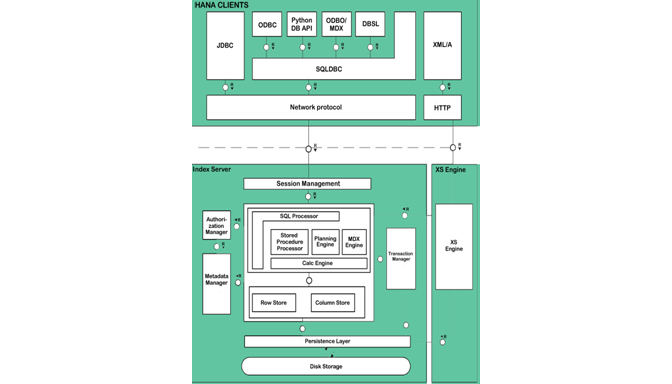
Indexer components:
The index server performs session management, authorization, transaction management and command processing.
The database has both a row store and a column store. Users can create tables using either store, but the column store has more capabilities and is most frequently used.
The index server also manages persistence between cached memory images of database objects, log files and permanent storage files.
The XS engine allows web applications to build. SAP HANA Information Modeling (also known as SAP HANA Data Modeling) is a part of HANA application development.
Modeling is the methodology to expose the operational data to the end user.
Reusable virtual objects are used in the modeling process.

MVCC:
SAP HANA manages concurrency through the use of multi-version concurrency control (MVCC) which gives every transaction a snapshot of the database at a point in time.
When an MVCC database needs to update an item of data, it will not overwrite the old data with new data, but will instead mark the old data as obsolete and add the newer version.
Streaming and Data Virtualization:
i. Data Virtualization is available via a tool named Smart Data Access.
ii. Streaming data, for example from the Internet, of things, devices are available via a tool named Smart Data Streaming.
iii. Dedicated streaming analytics(predictive analytics) can be employed against the data ingested by Smart Data Streaming.
If you have done with Setup then you can have a look about SAP HANA Security Tutorial.

Mahesh J
Author
Hello all! I’m a nature’s child, who loves the wild, bringing technical knowledge to you restyled.