Introduction to Informatica Data Quality (IDQ)
Informatica Data Quality:
Do you want quality mass data management? Do you want a data warehouse?
Want to prevent expensive data problems? Need more visibility and relevance?
This blog posts I’m writing today is as simple and important as it gets. I’m going to introduce you to Informatica Data Quality (IDQ) today.
Identify, resolve, and prevent costly data problems.
Let’s dive in!
Informatica has the largest priority for creating a data warehouse by using its powerful ETL tool, Informatica Power Center. Informatica ensures the data warehouse with quality data by providing a tool called Informatica Data Quality (IDQ).

Informatica Data Quality provides clean, high-quality data despite size, data format, platform, or technology.
It ensures validating and improving address information, profiling, and cleansing business data, or implementing a data governance practice, and other data quality requirements. Informatica Data Quality uses a unified platform to deliver quality data for all business initiatives and applications.
It allows you to proactively discover, profile, monitor, and cleanse your data in a consistent and reusable manner- regardless of the underlying platform and technologies.
Get Free Informatica IDQ Materials
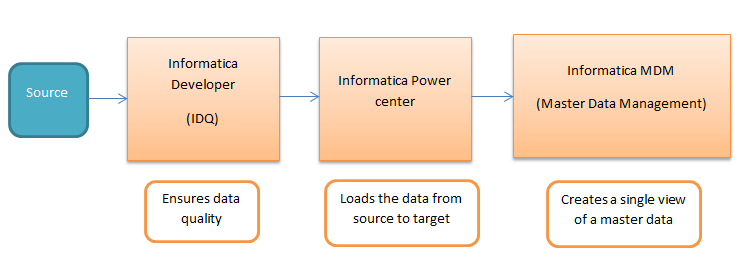
The source data is sent to the Informatica developer tool (IDQ) for cleansing and standardizing the data which ensures the quality of the data. Then the cleansed data is sent to the Informatica power center for loading the data from source to target tables.
The data in the target table is sent to Informatica MDM (Master Data Management) to create the golden record (single view) of a master data.
Data Quality Projects – Where to start?
Step 1: Profiling the Data (Analyst Task)
Three files/tables exist:
Orders: This contains Customer order information such as OrderID, PONumber, and Customer ID
And Order and Shipping Dates
Order Details: This contains information on the actual order such as the Item number, Item
Description and Unit Cost price.
Customer Shipping: This contains the Customer Shipping Address and customer information.
Data profiling is used to identify problems with completeness (what data is missing), conformity
(What data is held in non-standard format), and consistency (data in one field being inconsistent with data in another field in the same record). We need to identify the problems in the data before we can begin to cleanse and standardize it.
Step 2: Standardizing the data (Analyst and Developer Task)
Once the data has been profiled, the analyst can identify anomalies and decide on the standardization that needs to be performed.
These requirements can be documented within the profile which will enable analysts and developers to collaborate on projects.
The analyst can create the reference tables that the developers need to standardize, cleanse and enrich the data. Once mapplets have been developed by the developers, they can be reviewed by the analyst and modified if required.
The data analyst and developer can easily collaborate and transfer project related knowledge using the Analyst and Developer Tools.
This symbiotic transfer of information and ease of communication on projects helps reduce misunderstandings and ensure project success.

Step 3: Address Validation (Developer Task using input from the Analyst)
Once the data has been cleansed and standardized the next step would be to ensure the addresses are accurate by validating and enhancing them using definitive reference data from international postal agencies. This is a developer task performed in the Developer Tool.
Step 4: Matching (Developer Task using input from the Analyst)
Once the data has been cleansed and standardized, duplicate records can be identified using various different matching techniques. This is also a developer task performed in the Developer Tool.
Step 5: Consolidation (Developer and Analyst Task)
Using business rules defined by the analyst, the developer can build mappings, automatically or manually, to consolidate the matched records. Automatic Consolidation: The developer can build mappings to consolidate the matched records using rules defined by the analyst.
They can take the “best” value from each field across a record and use these to create a new “master” record made up of these specially selected values.
Manual Consolidation: The developer can build mappings, using rules defined by the analyst, to populate “bad records” and “duplicate records” table in IDD (Informatica Data Director).
This allows tasks to be assigned to users and will enable them to manually correct bad records and consolidate duplicate records.
To learn about tutorials, interview questions and answers, and more, read more about informatica IDQ on our blogs.

Mahesh J
Author
Hello all! I’m a nature’s child, who loves the wild, bringing technical knowledge to you restyled.